GOW

domingo, 19 de dezembro de 2021

quarta-feira, 3 de novembro de 2021
Como instalar no Ubuntu o MAME para jogar jogos clássicos de arcade

Quando usado em conjunto com imagens de ROM e disco de dados do jogo de arcade original, MAME tenta reproduzir esse jogo tão fielmente quanto possível.
O emulador suporta mais de 7000 jogos clássicos de arcade da era da década de 1970 até a atual.
De acordo com a página do software, MAME é gratuito e sem fins lucrativos. Seu principal objetivo é ser uma referência para o funcionamento interno das máquinas de arcade emulados.
Isso é feito tanto para fins educacionais e para fins de preservação, a fim de evitar que muitos jogos históricos desapareçam para sempre, uma vez que o hardware em que são executados não funcionam mais.
É claro que, a fim de preservar os jogos e demonstrar que o comportamento emulado corresponda ao original, você também deve ser capaz de realmente jogar os jogos. Este é considerado um bom efeito colateral, mas não é o foco principal do MAME.
Na página do projeto é possível encontrar diversas ROMs que graças à generosidade de alguns dos criadores originais de jogos clássicos de arcade, foram liberadas para gratuitamente para uso não comercial.
Com isso, além de fornecer o emulador, o site ainda entrega as ROMs necessárias para jogar os jogos clássicos de arcade que você tanto quer.
No tutorial a seguir, você verá como instalar MAME no Ubuntu e sistemas derivados.
Como instalar o MAME para jogar jogos clássicos de arcade
Para instalar o MAME no Ubuntu e ainda poder receber automaticamente as futuras atualizações dele, você deve fazer o seguinte:
Passo 1. Abra um terminal (use as teclas CTRL + ALT + T);
Passo 2. Se ainda não tiver, adicione o repositório do programa com este comando ou use esse tutorial;
sudo add-apt-repository ppa:c.falco/mame -yPasso 3. Atualize o gerenciador de pacotes com o comando:
sudo apt-get updatePasso 4. Agora use o comando abaixo para instalar o programa;
sudo apt-get install mameComo instalar o MAME manualmente ou em outras distros
Se não quiser adicionar o repositório ou quer tentar instalar em outra distribuição baseada em Debian, você pode pegar o arquivo DEB do programa nesse link e instalar ele manualmente (clicando duas vezes nele).
Mas lembre-se! Ao optar por esse tipo de instalação, você não receberá nenhuma atualização do programa.
Configurando o MAME
Se ainda não estiver sendo executado, abra um terminal e inicie o programa, digitando mame, para que ele crie a pasta do programa.
Em seguida, feche o emulador e depois execute o comando abaixo, para criar o arquivo de configuração para o MAME;
cd ~/.mame && mame -ccO arquivo “mame.ini” será criado na pasta ~/.mame.
Agora, edite este arquivo com o comando baixo (se você estiver no Linux Mint, substitua o gedit por pluma);
gedit ~/.mame/mame.iniEm “rompath”, você pode definir o seu próprio caminho de diretório ROM ou deixar os caminhos padrão. Depois de alterar, salve e feche o arquivo;

Em seguida, crie os diretório nvram, sta, roms, memcard, inp, comments, snap e diff na pasta ~/.mame, usando este comando;
mkdir ~/.mame/nvram memcard roms inp comments sta snap diffFinalmente, você pode acessar a pasta rom com o comando abaixo, para colocar suas roms baixadas nela e depois executar o emulador para jogar. Para baixar ROMs, acesse esse a página do MAME dedicada ao assunto;
sudo nautilus /usr/local/share/games/mame/romsQuanto aos controles do player, você pode facilmente configurá-los a partir da interface principal do MAME, usando a opção “Configure General Inputs”. Depois disso, sempre que quiser você pode jogar seus jogos clássicos de arcade.
Desinstalando o MAME no Ubuntu e derivados
Para desinstalar o MAME no Ubuntu e derivados, faça o seguinte:
Passo 1. Abra um terminal;
Passo 2. Desinstale o programa, usando o comando abaixo;
sudo add-apt-repository ppa:c.falco/mame -r -ysudo apt-get remove mame --auto-removedomingo, 25 de julho de 2021
segunda-feira, 21 de junho de 2021
UNIVERSO
Os astrofísicos, assim como muitos cientistas, não param de se fazer perguntas. E, apesar dos avanços neste campo, há mistérios que não conseguem explicar sem qualquer sombra de dúvida.
Por isso, estabeleceram teorias que, mesmo não podendo ser observadas ou comprovadas diretamente, são a única explicação encontrada até hoje para que as coisas sejam como são.
Conheça a seguir aqui algumas delas.
1. A matéria escura
A matéria escura, como diz o nome, não tem luz. Não absorve nem emite radiação, por isso, não pode ser vista diretamente.
Os cientistas sabem que ela existe pelo efeito gravitacional que exerce sobre outros elementos com matéria e sobre a estrutura do Universo.
Muitos especialistas acreditam que é composta por partículas massivas que interagem sem força entre elas e, por essa razão, nunca puderam ser detectadas.

Crédito, Getty Images
A matéria escura carece de luz, e os astrofísicos não conseguem detectá-la, apesar de saber que está ali
2. A energia escura
Os cientistas acreditam que há algo que contraria a força gravitacional de atração e, além disso, explicaria uma coisa aparentemente sem lógica: a constante expansão do Universo.
A gravidade por si só deveria evitar que isso acontecesse, mas na prática não garante isso.
Não é possível detectar a energia escura e os cientistas não conseguem comprovar sua existência, mas essa é a única explicação que encontraram. Acredita-se que esta energia represente 70% do Universo.
3. A inflação cósmica
Para poder explicar alguns enigmas que a teoria do Big Bang não respondia, os físicos conceberam um conjunto de teorias que chamaram de inflação cósmica.
Desta maneira, explicaram como o Universo se expandiu de maneira uniforme e de forma muito rápida há 13,8 bilhões de anos.
Se olharmos para o Universo, podemos ver uma esfera que parece se estender por partes iguais em todas as direções.
Os cientistas não entendiam como parecia haver uma temperatura uniforme: como duas partes distantes do Universo podem ter a mesma temperatura e densidade sem ter estado em contato?

Crédito, Getty Images
Com a inflação cósmica, houve partes do Universo que ficaram mais densas em matéria, e isso explicaria as galáxias e outros fenômenos
A inflação cósmica explica esse fenômeno. A teoria sugere que essas partes chegaram a formar uma unidade e que, menos de um bilionésimo de segundo depois do Big Bang, o universo sofreu um crescimento exponencial que as separou a uma velocidade superior à da luz devido à expansão espaço-temporal.
É como se o Universo fosse um globo vazio que se inflou de forma repentina e em grande velocidade, expandindo sua matéria.
Durante essa expansão, houve pequenas diferenças de temperaturas, pontos de maior densidade que se materializaram em galáxias e grupos de galáxias.
Também se produziram as ondas gravitacionais previstas por Albert Einstein.
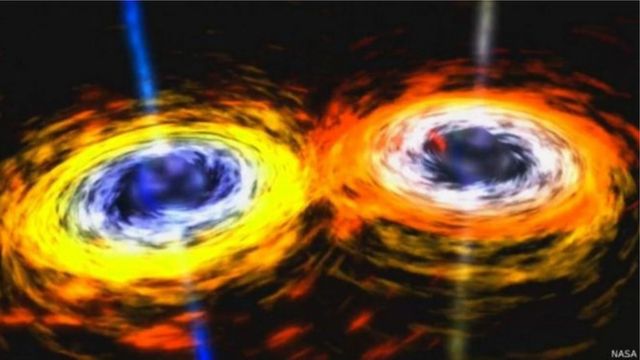
As ondas gravitacionais previstas por Einstein são geradas por distorções no espaço-tempo | Foto: Nasa
Portanto, os físicos não podem atestar o que formou esses conjuntos de estrelas e essas ondas, já que foram incapazes de observar isso, mas um fenômeno como a inflação cósmica pode fazer com que ele seja mais compreensível.
4. O destino do Universo
Uma das perguntas fundamentais para os cientistas é "para onde vamos?". A crença geral é que isso dependeria de um fator desconhecido que mede a densidade da matéria e a energia que há no cosmos.
Se considerarmos que esse fator é maior que a unidade, o Universo seria uma esfera. Sem a energia escura mencionada antes, o Universo deixaria de se expandir e tenderia a se contrair, o que provocaria o colapso absoluto.
Mas, como essa energia existe, os cientistas acreditam que o Universo seguirá se expandindo de maneira infinita.

Crédito, Getty Images
No Universo, espaço e tempo se modificam mutuamente
5. A entropia
Em teoria, o tempo sempre anda para frente. Isso se explica por uma propriedade da matéria chamada entropia, que é a quantidade de desordem de um sistema. Neste caso, a das partículas do Universo.

Crédito, Getty Images
Cientistas duvidam que o tempo tenha corrido sempre para a frente, mas não conseguem provar o contrário
Esse movimento é irreversível, mas suscita um novo enigma para os cientistas: por que o universo era tão organizado em seu início?
Se, como foi confirmado em outras teorias, havia uma grande quantidade de energia acumulada em um espaço tão reduzido, por que a entropia (a desordem) era tão baixa na origem do cosmos?
Ainda não há resposta para isso.
6. Os Universos paralelos
Nada nos garante que o Universo em que vivemos e o qual observamos (o visível) seja o único existente. Aparentemente, o espaço-tempo é uma extensão plana, infinita e não curva.
Muitos cientistas defendem a hipótese de que é possível que o que chamamos de Universo seja somente um entre outros infinitos espaços.
As leis da física quântica dizem que a configuração das partículas dentro de cada espaço é finita e que esta configuração deve, necessariamente, se repetir, o que implicaria em uma infinidade de Universos paralelos.
O que vem a ser o OpenShift?
O OpenShift é uma plataforma de código aberto desenvolvida pela Red Hat que auxilia no processo de orquestração de containers baseada em Kubernetes e containers Linux de maneira independente da plataforma na qual os containers serão executados.
Através de uma interface muito amigável e intuitiva, o OpenShift oferece a possibilidade de controlar todo o ciclo de vida de uma aplicação baseada em containers, desde o deploy até a execução efetiva.
Isso é possível graças a integração facilitada com várias outras ferramentas e SDKs para diferentes linguagens, o que torna o OpenShift uma ferramenta muito competente e completa não somente para o gerenciamento de containers, mas também para o controle de todo o ciclo de vida de uma aplicação.
O diagrama abaixo, fornecido pela própria Red Hat, oferece uma visão geral das ferramentas que são integradas e orquestradas pelo OpenShift.

Curso Docker - Gerenciamento de Imagens
Conhecer o cursoPela imagem acima, podemos perceber que o OpenShift oferece uma infinidade de serviços, como gerenciamento dos processos de integração contínua/entrega contínua (CI/CD), gerenciamento de configurações e logs, monitoramento da saúde das aplicações e containers que estão sendo gerenciados e até mesmo aspectos de segurança, isso tudo de maneira completamente desacoplada do container e/ou da infraestrutura que você esteja utilizando.
Segundo a Red Hat, o OpenShift consegue oferecer todos estes serviços por ser fundamentado em uma arquitetura baseada em microsserviços que conseguem se “encaixar” uns aos outros e prover as diferentes funcionalidades que cada projeto necessita.
Como o OpenShift funciona?
Segundo a Red Hat, o OpenShift funciona em cima de um sistema baseado em camadas, onde cada camada é responsável por determinada funcionalidade. A sobreposição destas camadas é que faz com que o OpenShift consiga oferecer a quantidade de funcionalidades que são oferecidas.
A imagem abaixo, retirada da própria documentação do OpenShift ilustra estas sobreposições de camadas.

Curso Docker - Fundamentos
Conhecer o cursoNo diagrama acima, percebemos inicialmente um benefício importantíssimo do OpenShift: ele é agnóstico a ferramentas de Continuous Integration/Continuous Delivery e também a ferramentas de automação de operações, como ferramentas de automação de provisionamento de infraestrutura. Isso quer dizer que você pode utilizar o OpenShift com o Jenkins, CircleCI, TravisCI, GitLab, Terraform ou qualquer uma das ferramentas desse nicho.
O OpenShift roda em cima de cluster baseado no Kubernetes, cluster no qual os componentes são organizados em um esquema de microsserviços. Estes componentes do coração do OpenShift ficam em um nó master dentro dessa infraestrutura. Entre estes componentes que ficam dentro desse nó master, podemos destacar:
- API/Authentication: controle de acesso às APIs do OpenShift e do Kubernetes. Esse processo de autenticação é baseado no padrão OAuth e em certificados SSL;
- Data Store: responsável por armazenar o estado e outras informações e meta-informações dos componentes do OpenShift. O OpenShift geralmente utiliza o etcd, uma estrutura de armazenamento baseada em chave/valor, para realizar o armazenamento destes dados;
- Scheduler: responsável por distribuir as cargas de trabalho entre nós dos clusters de componentes do OpenShift. Trata-se de um dos principais componentes do OpenShift;
- Management/Replication: mecanismo responsável pelo processo de replicação e por coletar informações sobre o estado dos componentes e elementos do cluster. Ele é basicamente um loop infinito que, de tempos em tempos, coleta estes dados e atualiza o estado dos componentes, armazenando estes estados no Data Store (etcd). Estes processos são controlados através de estruturas chamadas controllers. Os principais controllers dentro do OpenShift são: replication controller, endpoint controller, namespace controller e service account controller. É importante salientar que as informações coletadas pelos controllers refletem na API exposta pelo nó master, assim como os comandos dados às APIs do OpenShift e do Kubernetes são executados de fato também pelos controllers.
As aplicações acabam ficando armazenadas nos outros nós da infraestrutura do OpenShift. Na ilustração acima, por exemplo, temos uma estrutura inspirada no Docker: temos as aplicações dentro de containers, containers estes que ficam agrupados pelos pods. Todos estes pods desenvolvem seu ciclo de vida dentro de um nó, ou seja: uma máquina que faz parte do cluster Kubernetes gerenciado pelo OpenShift.
A relação entre o OpenShift e o OKD
O OKD é basicamente uma distribuição “personalizada” do Kubernetes. OKD é um acrônimo para “Origin Kubernetes Distribution”. O OKD foi criado pela Red Hat para que existisse uma distribuição do Kubernetes mais otimizada para processos tradicionais em ambientes baseados em nuvem, como aplicações multi-tenancy e aplicação de processos de continuous delivery/continuous integration. Ou seja: o OKD é um Kubernetes otimizado para as situações previamente citadas, otimizações estas realizadas pela Red Hat.
O OKD não é concorrente do OpenShift. Na verdade, o core do OpenShift é justamente o OKD. A estrutura baseada em Kubernetes que é utilizada pelo OpenShift é, na verdade, o OKD. Caso você julgue necessário, você pode utilizar o OKD de maneira direta, ou seja: sem passar necessariamente pelo OpenShift.
quinta-feira, 10 de junho de 2021
UNIVERSO
O Universo em toda a sua extensão oferece um vasto campo de estudo e especulação para astrônomos e cientistas. E quanto mais a ciência avança e novas descobertas são feitas, mais perguntas surgem sobre o funcionamento do Espaço, sobre a nossa própria origem e até mesmo sobre as possibilidades do Universo chegar ao fim.
Alguns dos mistérios que intrigam os pesquisadores envolvem fenômenos que fogem da compreensão e que levantam dúvidas sobre as razões de suas peculiaridades. É o caso da galáxia em formato retangular e do campo magnético em parte da crosta lunar. Descubra as dez principais perguntas sobre o Universo que ainda tiram o sono de muitos astrônomos e cientistas nos dias de hoje.
1. O que é a matéria escura?
No modelo cosmológico aceito pela comunidade científica, o Universo é composto por energias e partículas que interferem na gravidade, expansão e aceleração do espaço. Acredita-se que 73% da densidade se constitui de energia escura, que teria o efeito de pressão negativa sobre o Universo; e 23% de matéria escura, que hipoteticamente tem efeitos gravitacionais em matérias visíveis.
Por ser completamente invisível para telescópios e por não emitir luz nem radiação eletromagnética, a matéria escura é extremamente difícil de ser estudada. Os cientistas especulam que ela seja composta de partículas subatômicas diferentes daquelas das matérias visíveis, mas seu efeito gravitacional é perceptível nos movimentos de galáxias e estrelas.
Um dos principais recursos para o estudo da matéria escura é o projeto AMS (Alpha Magnetic Spectrometer) na Estação Espacial Internacional, que coleta dados sobre o fluxo de raios cósmicos na órbita da Terra. Leia mais aqui sobre essa pesquisa científica.
2. O magnetismo nas crateras da Lua
Um dos maiores mistérios da Lua, assim como a sua origem e formação, é a presença de campos altamente magnetizados na superfície, mas apenas em algumas partes da crosta e não em sua totalidade. A região da bacia do Polo Sul-Aitken, onde se encontra a maior cratera na superfície da Lua, apresenta também a maior concentração de magnetismo do satélite e tem despertado a atenção dos cientistas.
 Fonte da imagem: Reprodução/Smithsonian.com
Fonte da imagem: Reprodução/Smithsonian.com
Acredita-se que essa grande cratera foi formada pelo impacto de um asteroide de 200 quilômetros de extensão, há cerca de 4,5 bilhões de anos. Esse asteroide pode ter deixado uma quantidade enorme de alguma forma de ferro, que se espalhou de maneira irregular pela crosta lunar, produzindo essas anomalias magnéticas ainda hoje detectadas.
Os cientistas especulam também se a Lua tinha algum tipo de campo eletromagnético depois da sua formação, que estaria presente inclusive no evento do grande impacto do asteroide, mas que foi desaparecendo ao longo do tempo. Simulações por computador indicam que o campo lunar de fato existiu e que o magnetismo encontrado em regiões da superfície faz parte tanto de materiais do espaço quanto de restos do campo eletromagnético que ainda resistem no satélite.
3. A galáxia retangular
A galáxia anã LEDA 074886, detectada em 2012, está localizada a 70 milhões de anos-luz, mas mesmo à longa distância ela chama a atenção pelo seu aspecto retangular. As galáxias em geral têm formato oval, como discos, elipses tridimensionais, às vezes até com curvaturas irregulares, mas essa nova galáxia tem uma aparência bastante peculiar, com cantos mais definidos.
 Fonte da imagem: Reprodução/Smithsonian.com
Fonte da imagem: Reprodução/Smithsonian.com
De acordo com algumas especulações, o aspecto retangular pode ser resultado da colisão de duas galáxias em formato espiral. A LEDA 074886 pode ser vista como um retângulo ou até mesmo se assemelhando a um diamante, mas apresenta um disco de orientação circular no centro. Acredita-se que a galáxia deve perder seus cantos duros ao longo de bilhões de anos.
4. O problema de lítio
O lítio é um dos elementos, junto com o hélio e o hidrogênio, que deveria ser abundante no Universo por estar diretamente ligado aos processos de síntese nuclear. Porém, a observação de estrelas antigas, formadas de material similar àquele que produziu o Big Bang, revelou uma quantidade de lítio muito inferior do que previam os modelos teóricos. A pouca quantidade do elemento nas estrelas ficou conhecida no meio científico como “problema de lítio”.
Novas pesquisas indicam que parte desse lítio pode estar misturada ao centro das estrelas, fora da vista de telescópios. Ao mesmo tempo, no campo teórico, pesquisadores sugerem que áxions, partículas subatômicas hipotéticas, podem ter absorvido prótons e reduzido a quantidade de lítio criada logo após o Big Bang.
5. A reciclagem do Universo
Nos anos mais recentes, os astrônomos notaram que as galáxias formam novas estrelas a uma taxa que parece consumir mais matéria do que elas pareciam ter. Um novo estudo com galáxias distantes pode ter encontrado a resposta a este mistério. As galáxias parecem atrair de volta para o seu centro um gás que elas mesmo produzem, o que pode resolver a questão da origem da matéria bruta na formação de novas estrelas.
6. As bolhas de radiação no centro da Via Láctea
O telescópio Fermi, capaz de detectar raios gama no espaço, registrou em 2010 gigantescas bolhas de radiação que emanam em direções opostas a partir do centro da Via Láctea. Essas estruturas se estendem a 20 mil anos-luz para cima e para baixo do plano espacial.
 Fonte da imagem: Reprodução/Smithsonian.com
Fonte da imagem: Reprodução/Smithsonian.com
Os cientistas têm especulado que essa radiação pode ser resultado do choque de estrelas sendo consumidas pelo enorme buraco negro do centro da galáxia.
7. Por que as pulsares pulsam?
As estrelas de nêutrons pulsares têm a particularidade de emitir radiação eletromagnética em intervalos regulares, como o feixe de luz em rotação de um farol. Apesar de a primeira pulsar ter descoberta em 1967, os cientistas ainda tentam decifrar as causas dos pulsos de energia. Observou-se que correntes magnéticas influenciam no desalinhamento dos polos e na emissão de radiação, mas ainda não há explicação para a flutuação magnética que movimenta as pulsares.
8. Estamos sozinhos?
A pergunta que não quer calar: será que estamos sozinhos no Universo? Em 1961, o astrofísico Frank Drake postulou uma equação polêmica sugerindo que, levando em conta diversos fatores, a probabilidade de existir vida em outro lugar é extremamente alta. Drake contabilizou a formação de novas estrelas, a quantidade de estrelas com planetas, a combinação de condições para a existência de vida, entre outras especificações. Ainda não encontramos vida em nenhum canto da galáxia, mas isso não significa que devemos perder as esperanças.
9. O fim do Universo
Os teóricos acreditam que o Universo começou com o Big Bang, mas há muitas dúvidas ainda de como ele vai acabar. Não é possível saber se o Universo continuará se expandindo até o ponto da desagregação de toda a matéria, o Big Rip, ou se a expansão irá cessar e o plano espacial entrar em processo de condensação, o chamado Big Crunch.
10. Universos paralelos
Podemos não estar sozinhos e podemos não ser únicos. A teoria de pesquisadores físicos é de que podemos estar em um multiverso, com outros universos paralelos. A especulação sugere pensar o nosso universo como uma bolha, como um globo de neve, e que outros universos alternativos existem dentro de suas próprias bolhas. Apesar de ser um conceito bem próximo de clássicos da ficção científica, astrônomos procuram evidências que indiquem pontos de colisão entre os universos.
Hipótese do tempo-fantasma
Hipótese do tempo-fantasma
-
A hipótese do tempo-fantasma é teoria da conspiração afirmada pelo historiador alemão Heribert Illig.[1] Primeiro publicado em 1991, a hipótese propõe uma conspiração do Imperador Romano-Germânico Otão III, do Papa Silvestre II e possivelmente do imperador bizantino Constantino VII, para fabricar o sistema de datação retrospectivo do Anno Domini, de modo que os colocou no ano especial de 1000 d.C., e para reescrever a história[2] para legitimar a reivindicação de Otão ao Sacro Império Romano.[3] Illig acreditava que isso foi alcançado através da alteração, deturpação e falsificação de evidências documentais e físicas.[4] De acordo com este cenário, todo o período carolíngio, incluindo a figura de Carlos Magno, é uma fabricação, com um tempo-fantasma de 297 anos (614-911 d.C.) adicionado à Alta Idade Média.
Segundo essa hipótese, o ano de 2017, seria na verdade 1719[5] ou 1720.[6]
Muitos dos historiadores do mundo criticaram a hipótese e afirmam que as datas dos eclipses solares foram registradas e as histórias foram documentadas de outras partes ao redor do globo que se sobrepõem a alguns dos períodos de tempo perdido.[7]
Heribert Illig
Illig nasceu em 1947 em Vohenstrauß, Baviera. Ele era ativo em uma associação dedicada a Immanuel Velikovsky sobre catastrofismo e revisionismo histórico, Gesellschaft zur Rekonstruktion der Menschheits- und Naturgeschichte. De 1989 ao 1994 trabalhou como editor do jornal Vorzeit-Frühzeit-Gegenwart. Desde 1995, trabalhou como editor e autor sob sua própria editora, Mantis-Verlag, e publicando seu próprio periódico, Zeitensprünge. Fora a suas publicações relacionadas à cronologia revisada, ele editou as obras de Egon Friedell.
Antes de se concentrar no início do período medieval, Illig publicou várias propostas para cronologias revisadas da pré-história e do Antigo Egito. Suas propostas receberam uma cobertura proeminente na mídia popular alemã na década de 1990. Sua de 1996 Das erfundene Mittelalter (A Idade Média Inventada, tradução livre) também recebeu críticas acadêmicas, mas foi universalmente rejeitado como fundamentalmente falho pelos historiadores. Em 1997, a revista Ethik und Sozialwissenschaften ofereceu uma plataforma para discussão crítica para a proposta de Illig, com uma série de historiadores comentando seus vários aspectos. Depois de 1997, houve pouca recepção acadêmica das ideias de Illig, embora continuassem a ser discutidas como pseudo-história na mídia popular alemã. Illig continuou a publicar sobre a "hipótese do tempo-fantasma" até pelo menos 2013. Também em 2013, ele publicou um tópico não relacionado da história da arte, sobre o mestre do Renascimento alemão Anton Pilgram, mas novamente propôs revisões à cronologia convencional e defendendo a abolição da categoria Maneirismo da história da arte.
Proposta
As bases da hipótese de Illig incluem:
- A escassez de evidências arqueológicas que podem ser datadas de forma confiável para o período 614-911 d.C., as deficiências percebidas dos métodos radiométricos e dendrocronológicos de datação neste período e a excessiva dependência dos historiadores medievais de fontes escritas.
- A presença da arquitetura românica na Europa ocidental do século X, sugerindo que a Era Romana não era tão antiga como se pensava convencionalmente.
- A relação entre o calendário juliano, o calendário gregoriano e o ano solar ou tropical astronômico subjacente. O calendário juliano, apresentado por Júlio César, era há muito conhecido por apresentar uma discrepância do ano tropical de cerca de um dia para cada século que o calendário estava em uso. No momento em que o calendário gregoriano foi introduzido em 1582 d.C., Illig alega que o antigo calendário juliano deveria ter produzido uma discrepância de treze dias entre ele e o calendário real (ou tropical). Em vez disso, os astrônomos e matemáticos que trabalhavam para o Papa Gregório XIII descobriram que o calendário civil precisava ser ajustado em apenas dez dias. (O dia do calendário juliano, quinta-feira, 4 de outubro de 1582, foi seguido pelo primeiro dia do calendário Gregoriano, sexta-feira, 15 de outubro de 1582). Com isso, Illig conclui que a era d.C. tinha contado cerca de três séculos que nunca existiram.
Críticas
- O desafio mais difícil para a teoria é através de observações em astronomia antiga, especialmente as de eclipses solares citados por fontes europeias antes de 600 d.C. (quando o tempo fantasma teria distorcido a cronologia). Além de vários outros que são talvez muito vagos para refutar a hipótese do tempo fantasma, dois em particular são datados com precisão suficiente para refutar a hipótese com um alto grau de certeza. Um é relatado por Plínio, o Velho em 59 d.C. e um por Fócio em 418 d.C. Ambas as datas e horários confirmaram eclipses. Além disso, as observações durante a Dinastia Tang na China e o Cometa Halley, por exemplo, são consistentes com a astronomia atual sem acrescentar tempo-fantasma.
- Os restos arqueológicos e os métodos de datação como a dendrocronologia refutam, em vez de suportar, o tempo-fantasma.
- A reforma Gregoriana nunca pretendeu ajustar o calendário ao calendário Juliano, tal como existia na época de sua instituição em 45 a.C., mas, como existia em 325, o tempo do Concilio de Niceia, que havia estabelecido uma método para determinar a data do Domingo de Páscoa fixando o Equinócio Vernal em 21 de março no calendário Juliano. Em 1582, o equinócio astronômico estava ocorrendo em 10 de março no calendário juliano, mas a Páscoa ainda estava sendo calculada a partir de um equinócio nominal em 21 de março. Em 45 a.C., o equinócio vernal astronômico ocorreu em 23 de março. Os "três séculos ausentes" de Illig correspondem aos 369 anos entre a instituição do calendário juliano em 45 a.C. e a fixação da data de Páscoa no Concílio de Niceia em 325 d.C.
- Se Carlos Magno e a dinastia Carolíngia fossem fabricadas, teria que haver uma fabricação correspondente da história do resto da Europa, incluindo a Inglaterra anglo-saxônica, o Papado e o Império Bizantino. O período do tempo-fantasma abrange também a vida de Maomé e a expansão islâmica nas áreas do antigo Império Romano, incluindo a conquista da Ibéria Visigoda. Esta história também teria que ser forjada ou drasticamente distorcida. Deveria também conciliar-se com a história da Dinastia Tang da China e seu contato com o Islã, como na Batalha de Talas.
Referências
- «Confira a lista abaixo das 10 teorias da conspiração mais fantasiosas e reflita». hypescience.com
- Hans-Ulrich Niemitz, Did the Early Middle Ages Really Exist? pp. 9–10.
- http://www.cl.cam.ac.uk/~mgk25/volatile/Niemitz-1997.pdf
- Fomenko, Anatoly (2007). History: Chronology 1: Second Edition. [S.l.]: Mithec. ISBN 2-913621-07-4
- «A VERDADE POR TRÁS DE 5 CONSPIRAÇÕES GLOBAIS QUE AMEAÇAM A HUMANIDADE». Seu History. Consultado em 14 de outubro de 2017
- «Estamos vivendo no ano 1720, de acordo com a Hipótese do Tempo Fantasma». Ovni Hoje. Consultado em 14 de outubro de 2017
terça-feira, 8 de junho de 2021
quinta-feira, 27 de maio de 2021
Create Java application project with Hibernate
In this article, we will learn how to configure Hibernate in our Java project with Maven. There are some problems when doing with Hibernate, and we will solve them to know more about configuration in Hibernate.
Let’s get started.
Creating project using Maven
Belows are some steps that we need to create project with Maven:
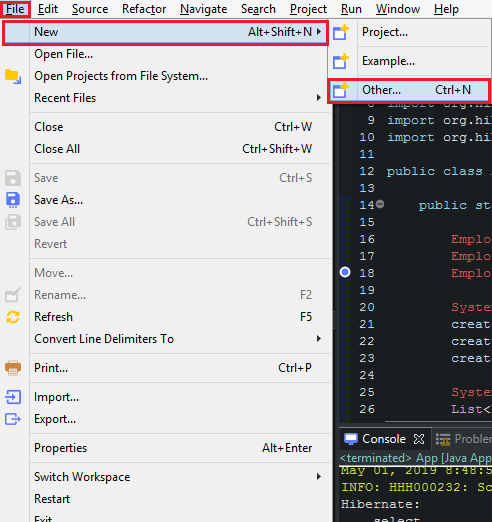
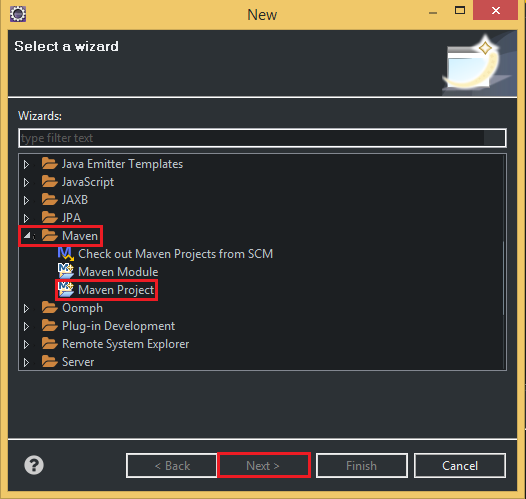
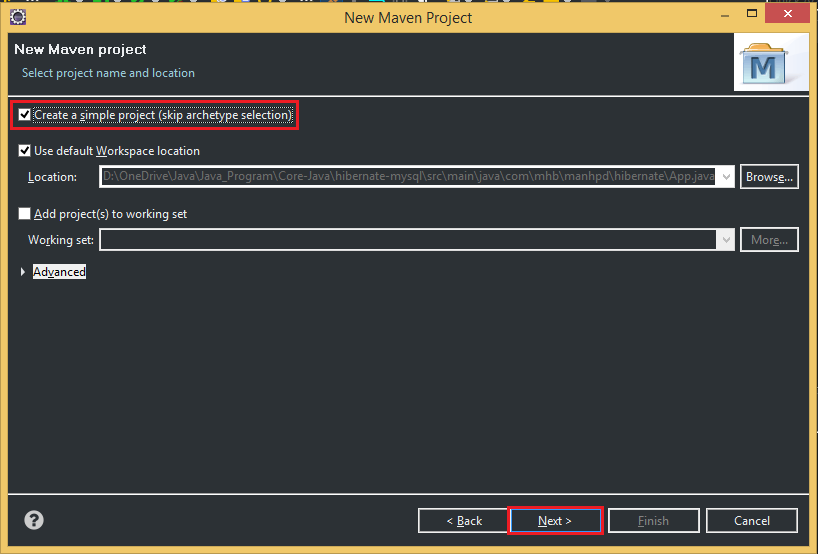
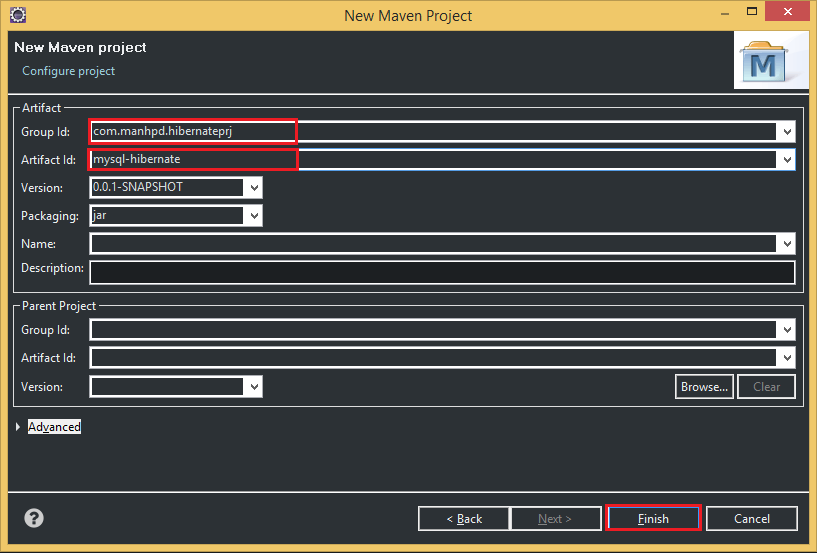
So, after passing all above steps, we have a project that is managed by Maven. When we want to add libraries, we can fill in
pom.xml file.Finally, we will have the structure of Maven project like the below image:
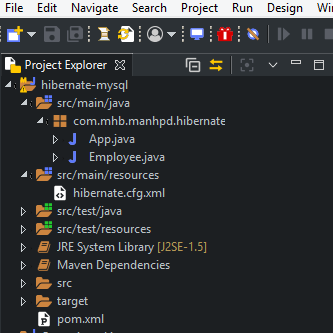
Preparing database in MySQL
In order to implement the communication between MySQL and Hibernate, we need to create our own database in MySQL. The following is the content of sql file that is used to create database and table
Employee.CREATE DATABASE java_sql;
USE java_sql;
CREATE TABLE `EMPLOYEE` (
ID INT NOT NULL AUTO_INCREMENT,
FULL_NAME VARCHAR(20) DEFAULT NULL,
AGE INT DEFAULT NULL,
PRIMARY KEY (ID)
);
INSERT INTO `employee` (ID, FULL_NAME, AGE)
VALUES
(1, "John", 56),
(2, "Bill Adam", 45),
(3, "Mary Smith", 78);
SELECT * FROM `employee`;
Add dependencies of Maven to pom.xml file
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.3.6.Final</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.18.0-GA</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.6</version>
<scope>provided</scope>
</dependency>
</dependencies>
Configuring xml file for Hibernate
All information about configurations of Hibernate is contained in a standard Java properties file called
hibernate.properties, or an XML file named hibernate.cfg.xml.In this article, we will use the
hibernate.cfg.xml file. It is located in src/main/resouces folder.The content of
hibernate.cfg.xml file like that:<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/java_sql</property>
<property name="hibernate.connection.useUnicode">true</property>
<property name="hibernate.connection.characterEncoding">UTF-8</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">12345</property>
<property name="hibernate.current_session_context_class">thread</property>
<property name="hibernate.hbm2ddl.auto">update</property>
<property name="hibernate.show_sql">true</property>
<property name="hibernate.format_sql">true</property>
<mapping class="com.mhb.manhpd.hibernate.Employee"/>
</session-factory>
</hibernate-configuration>
In MySQL, we should note that when we remove two properties such as
hibernate.connection.useUnicode, and hibernate.connection.characterEncoding. In Eclipse, we have an error like Exception in thread main org.hibernate.exception.JDBCConnectionException: Error calling Driver#connect.When we find DDL for
employee table, we have:CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Therefore, in our table, it uses charset that is utf8mb4 - UTF8 Unicode. In order that hibernate can communicate with MySQL succesfully, we have to set value for
hibernate.connection.useUnicode is true, and set value for hibernate.connection.characterEncoding is UTF-8.To show the MySQL default character set, we have to login to the MySQL console and execute
SHOW VARIABLES LIKE 'char%';.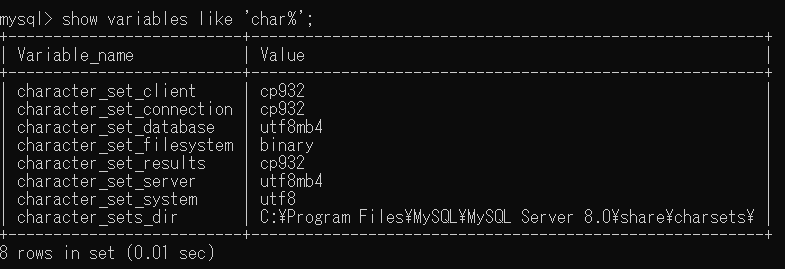
If we want to change it, for example, to utf8, we have to add this:
default-character-set = utf8
to the client,
mysqld_safe, mysqld and mysqldump section (may differ depending on configuration) in your my.cnf and restart the mysql daemon.We can go to this link to refer some information about configuration in Hibernate.
When we want to connect with the other RDBMSs, we will have some values of
hibernate.dialect, hibernate.connection.driver_class, and hibernate.connection.url.MySQL
<property name="hibernate.dialect">org.hibernate.dialect.MySQL57Dialect</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/database_name</property>
Oracle
<property name="hibernate.dialect">org.hibernate.dialect.Oracle12cDialect</property>
<property name="hibernate.connection.driver_class">oracle.jdbc.OracleDriver</property>
<property name="hibernate.connection.url">jdbc:oracle:thin:@localhost:1521/database_name</property>
PostgreSQL
<property name="hibernate.dialect">org.hibernate.dialect.PostgreSQL95Dialect</property>
<property name="hibernate.connection.driver_class">org.postgresql.Driver</property>
<property name="hibernate.connection.url">jdbc:postgresql://localhost:5432/database_name</property>
SQL Server
<property name="hibernate.dialect">org.hibernate.dialect.SQLServer2012Dialect</property>
<property name="hibernate.connection.driver_class">com.microsoft.sqlserver.jdbc.SQLServerDriver</property>
<property name="hibernate.connection.url">jdbc:sqlserver://localhost;instance=SQLEXPRESS;databaseName=java_sql</property>
MariaDB
<property name="hibernate.dialect">org.hibernate.dialect.MariaDB53Dialect</property>
<property name="hibernate.connection.driver_class">org.mariadb.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mariadb://127.0.0.1:port_number/java_sql</property>
Creating entity that is corresponding to a table in MySQL
We will generate entity that is mapped to data types of
employee table in MySQL.import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Entity
@Table(name = "employee")
@Data
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private int id;
@Column(name = "FULL_NAME")
private String name;
@Column(name = "AGE")
private int age;
public Employee() {
// nothing to do
}
public Employee(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Employee: " + this.id + ", " + this.name + ", " + this.age;
}
}
We have some rules for persistent class that we can apply to our own cases.
All Java classes that will be persisted need a default constructor.
All classes should contain an ID in order to allow easy identification of our objects within Hibernate and the database. This property maps to the primary key column of a database table.
All attributes that will be persisted should be declared private and have
getXXX() and setXXX() methods defined in the JavaBean style.A central feature of Hibernate, proxies, depends upon the peristent class being either non-final, or the implementation of an interface that declares all public methods.
All classes that do not extend or implement some specialized classes and interface required by the EJB framework.
Creating CRUD operations to MySQL
Fix some problems
If we modify Hibernate from EclipseLink, with one-to-one relationship or one-to-many relationship, we have error such as:
Multiple writable mappings exist for the field []. Only one may be defined as writable, all others must be specified read-only.
Source code for this problem:
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private int id;
private String email;
private String password;
private int reputation;
@OneToOne(mappedBy="user", cascade={CascadeType.ALL})
private Company company;
@OneToOne(mappedBy="user")
private Person person;
...
}
@Entity
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
@Column(name="id_user")
private int idUser;
@Temporal( TemporalType.DATE)
private Date birthdate;
private String gender;
private String name;
private String surname;
@OneToOne
@JoinColumn(name="id_user", insertable=false, updatable=false)
private User user;
}
public class Company implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
@Column(name="id_user")
private int idUser;
private String email;
private String name;
@ManyToOne
@JoinColumn(name="area")
private Area areaBean;
@OneToOne(cascade={CascadeType.ALL})
@JoinColumn(name="id_user", insertable=false, updatable=false)
private User user;
}
The reason for this error: we have the
id_user column mapped twice, once using a basic @Id mapping, and once using the @ManyToOne. We need to make one of them readonly, such as insertable=false, updatable=false in @JoinColumn annotation. Or better just remove the basic id, and put the @Id on the @ManyToOne.So, we have two way to solve this error:
Replace
@JoinColumn(name="area") as @PrimaryKeyColumn(name = "area", referencedColumnName = "id").Placing the insertable=false, updatable=false in the @JoinColumn annotation in both classes, Person and Company.
Assinar:
Postagens (Atom)