

Códigos são utilizados em todo o mundo por programadores.
É importante entender suas funções e como eles podem
ser utilizados para extrair o máximo de vantagens.
O ASCII
Existem diferentes códigos. O mais conhecido é o código
ASCII (American Standard Code for Information Interchange).
Este é um padrão americano, mas é um dos mais utilizados em todo o mundo.
O código ASCII define, com precisão,
a correspondência entre símbolos e números até o número 127:
Portanto, use o número 97 para representar um a minúsculo.

Para representar o ?, use o código 63. Alguns deles (os inferiores a 32)
são códigos de controle e não são feitos para serem exibidos.
Por exemplo, o código 10 pula a linha, o código 7 emite um sinal sonoro no computador,
entre outras funções.
Mas você reparou que não há caracteres acentuados?
Pois é, os americanos não pensaram no resto do mundo.
Muitas vezes usamos os códigos de 128 a 255
para os acentos, mas os códigos são diferentes de um país para outro.
Nada prático para trocar documentos.
Assim, foi preciso encontrar um código mais prático: o UNICODE.
O UNICODE
Em vez de usar apenas os códigos de 0 a 127,
o UNICODE utiliza códigos de valor bem maiores.
Com isso, pode representar todos os caracteres específicos de diversos idiomas.
Novos códigos são regularmente atribuídos para novos caracteres,
como caracteres latinos (acentuados ou não),
gregos, cirílicos, armênios, hebraicos, tailandeses,
hiraganas, katakanas etc. Só o alfabeto chinês Kanji contém 6.879 caracteres.
Assim sendo, o UNICODE define uma correspondência entre símbolos e números.
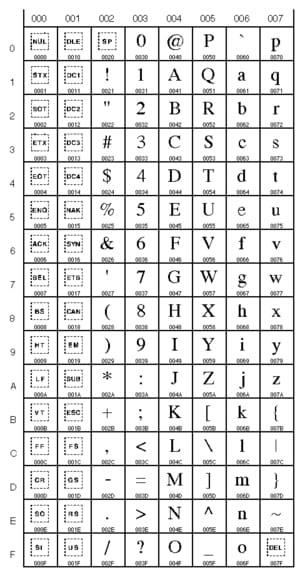
Veja uma pequena parte da tabela
UNICODE cujos números são apresentados em notação hexadecimal.
Primeiro, caracteres de 0000 a 007F (de 0 a 127 - caracteres latinos)::
Caracteres de 0080 a 00FF (de 128 a 255 - caracteres latinos com acentos):
Caracteres de 0900 a 097F (de 2304 a 2431 - caracteres devanagari):

Caracteres de 1100 a 117F (de 4352 a 4479 - caracteres hangul jamo):

Mesmo se o UNICODE foi bem desenvolvido,

pouca coisa foi utilizada em relação ao ASCII.
Não envie uma mensagem em UNICODE para alguém:
provavelmente esta pessoa não poderá lê-la.
Mesmo para os programadores, nem sempre é fácil de manipulá-lo.
Este padrão está crescendo cada vez mais. As linguagens Java
e Python já suportam o UNICODE. Grande parte dos sistemas operacionais
(Windows, Linux, MacOS X etc.) também já são capazes de lê-lo.
UNICODE na prática: UTF-8
Em teoria, o UNICODE é muito bom. Porém, na prática,
a história é outra. Normalmente, em UNICODE, um caractere usa 2 bytes. Em outras palavras, qualquer texto usa duas vezes mais espaço do que no ASCII. É um desperdício. Além disso, se tomarmos como exemplo um texto em português, a grande maioria dos caracteres só utiliza o código ASCII. São raros os caracteres que requerem UNICODE. Mas há um truque: o UTF-8.
Um texto em UTF-8 é simples, é feito completamente
em ASCII e, quando precisamos de um caractere do
UNICODE, usamos um caractere especial, que indica 'Atenção, o seguinte caractere está em UNICODE'.
Por exemplo, no texto 'Bienvenue chez Sébastien'
(Bem-vindo à casa de Sébastien, em francês), apenas
o 'é' não faz parte do código ASCII. Então, escrevemos em UTF-8:
De qualquer maneira, para ser mais rigoroso, indicamos

o início do arquivo, que está em UTF-8, com caracteres especiais:
O UTF-8 reúne a eficiência do ASCII e o âmbito do UNICODE.

Aliás, o UTF-8 foi adotado como padrão para a codificação de arquivos XML.
A maioria dos navegadores atuais também suportam o
UTF-8 e o detectam automaticamente nas páginas HTML.
Como fazer nas páginas web
Se você colocar diretamente o caractere 'é</bold'>
em uma página web, isto não é bom. Você deverá, obrigatoriamente,
escolher uma dessas três soluções:
Usar as entidades HTML e colocar '<bold>>é' no lugar do 'é';
Deixar o 'é' assim mesmo e especificar a codificação
de caracteres que você usará no início do arquivo HTML (na tag head):
<meta http-equiv="Content-type" content="text/html; charset=ISO-8859-1">(ISO-8859-1 é o conjunto de caracteres latinos em execução no Windows)
Trabalhar diretamente em UTF-8 no seu editor de HTML (se for possível).
Em seguida, acrescentar:
<meta http-equiv="Content-type" content="text/html; charset=UTF-8">O ISO-8859-1 é adequado para a maioria dos idiomas
latinos ou ocidentais (inglês, francês, alemão, espanhol etc.)
e o UTF-8 será indispensável para outras línguas (japonês, hebraico etc.).
Nenhum comentário:
Postar um comentário